Clustering Documents with OpenAI embeddings, HDBSCAN and UMAP
In the past, the most common way to cluster documents was by building vectors with traditional Machine Learning methods such as bag-of-words or smaller pre-trained NLP models, like BERT, and then creating groups out of them. But LLMs have changed that.
While older methods are still relevant, if I had to cluster text data today, I’d start using the OpenAI or Cohere (embeddings and generation) APIs. It’s faster, easier, and gives you additional goodies such as coming up with fitting titles for each cluster.
I haven’t seen many tutorials on this topic, so I wrote one. In this tutorial, I’ll show you how to cluster news articles using OpenAI embeddings, and HDBSCAN.
Let’s get to it!
Prerequisites
To make the most of this tutorial, you should be familiar with the following concepts:
- How to cluster text data using traditional ML methods.
- What are OpenAI Embeddings
- How HDBSCAN works
In addition, you’ll need an OpenAI account.
Set Up Your Local Environment
- Create a virtual environment using
venv:
- Create a
requirements.txtfile that contains the following packages:
- Activate the virtual environment and install the packages:
- Create a file called
.env, and add the your OpenAI key:
- Create an empty notebook file. For the rest of this tutorial, you’ll work on it.
Clustering Documents
You should think of the clustering process in three steps:
- Generate numerical vector representations of documents using OpenAI’s embedding capabilities.
- Apply a clustering algorithm on the vectors to group the documents.
- Generate a title for each cluster summarizing the articles contained in it.
That’s it! Now, you’ll see how that looks in practice.
Import the Required Packages
Start by importing the required Python libraries. Copy the following code in your notebook:
This code imports the libraries you’ll use throughout the tutorial. Here’s the purpose of each one:
oshelps you read the environment variables.hdbscangives you a wrapper of HDBSCAN, the clustering algorithm you’ll use to group the documents.openaito use OpenAI LLMs.umaploads UMAP for dimensionality reduction and visualizing clusters.dotenvload the environment variables you define in.env.
Next, you’ll get a sample of news articles to cluster.
Download the data and generate embeddings
Download, read these articles, and generate documents you’ll use to create the embeddings:
Then, initialize the OpenAI client and generate the embeddings:
Cluster documents
Once you have the embeddings, you can cluster them using hdbscan:
This code will generate clusters using the embeddings generated, and then create a DataFrame with the results. Itfits the hdbscan algorithm. In this case, I set min_samples and min_cluster_size to 3, but depending on your data this may change. Check HDBSCAN’s documentation to learn more about these parameters.
Next, you’ll create topic titles for each cluster based on their contents.
Visualize the clusters
After you’ve generated the clusters, you can visualize them using UMAP:
umap = UMAP(n_components=2, random_state=42, n_neighbors=80, min_dist=0.1)
df_umap = (
pd.DataFrame(umap.fit_transform(np.array(embeddings)), columns=['x', 'y'])
.assign(cluster=lambda df: hdb.labels_.astype(str))
.query('cluster != "-1"')
.sort_values(by='cluster')
)
fig = px.scatter(df_umap, x='x', y='y', color='cluster')
fig.show()You should get something similar to this graph:
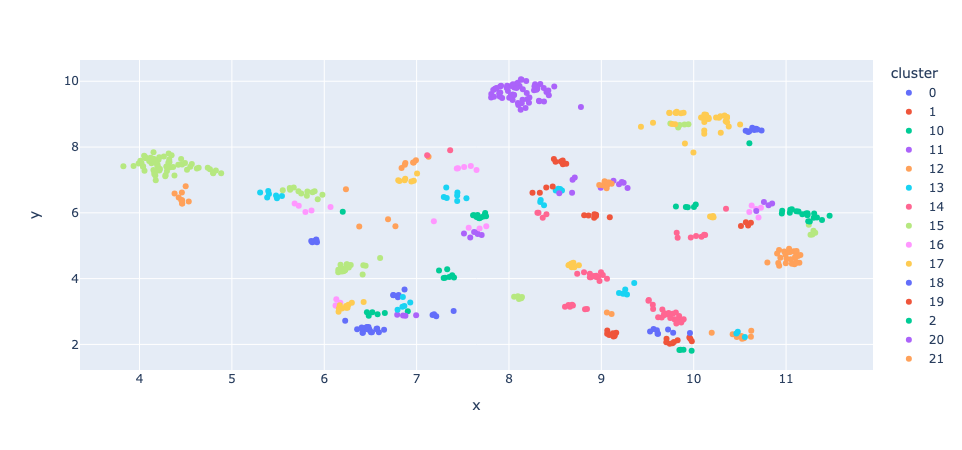
This will give you a sense of how good are the clusters generated.
Create a Topic Title per Cluster
For each cluster, you’ll generate a topic title summarizing the articles in that cluster. Copy the following code to your notebook:
df["cluster_name"] = "Uncategorized"
def generate_topic_titles():
system_message = "You're an expert journalist. You're helping me write short but compelling topic titles for groups of news articles."
user_template = "Using the following articles, write a 4 to 5 word title that summarizes them.\n\nARTICLES:\n\n{}\n\nTOPIC TITLE:"
for c in df.cluster.unique():
sample_articles = df.query(f"cluster == '{c}'").to_dict(orient="records")
articles_str = "\n\n".join(
[
f"[{i}] {article['title']}\n{article['description'][:200]}{'...' if len(article['description']) > 200 else ''}"
for i, article in enumerate(
sample_articles, start=1
)
]
)
messages = [
{"role": "system", "content": system_message},
{"role": "user", "content": user_template.format(articles_str)},
]
response = client.chat.completions.create(
model="gpt-3.5-turbo", messages=messages, temperature=0.7, seed=42
)
topic_title = response.choices[0].message.content
df.loc[df.cluster == c, "cluster_name"] = topic_titleThis code takes all the articles per cluster and uses gpt-3.5-turbo to generate a relevant topic title from them. Itgoes through each cluster, takes the articles in it, and makes a prompt using that to generate a topic title for that cluster.
Finally, you can check the resulting clusters and topic titles, as follows:
In my case, running this code produces the following articles and topic titles:
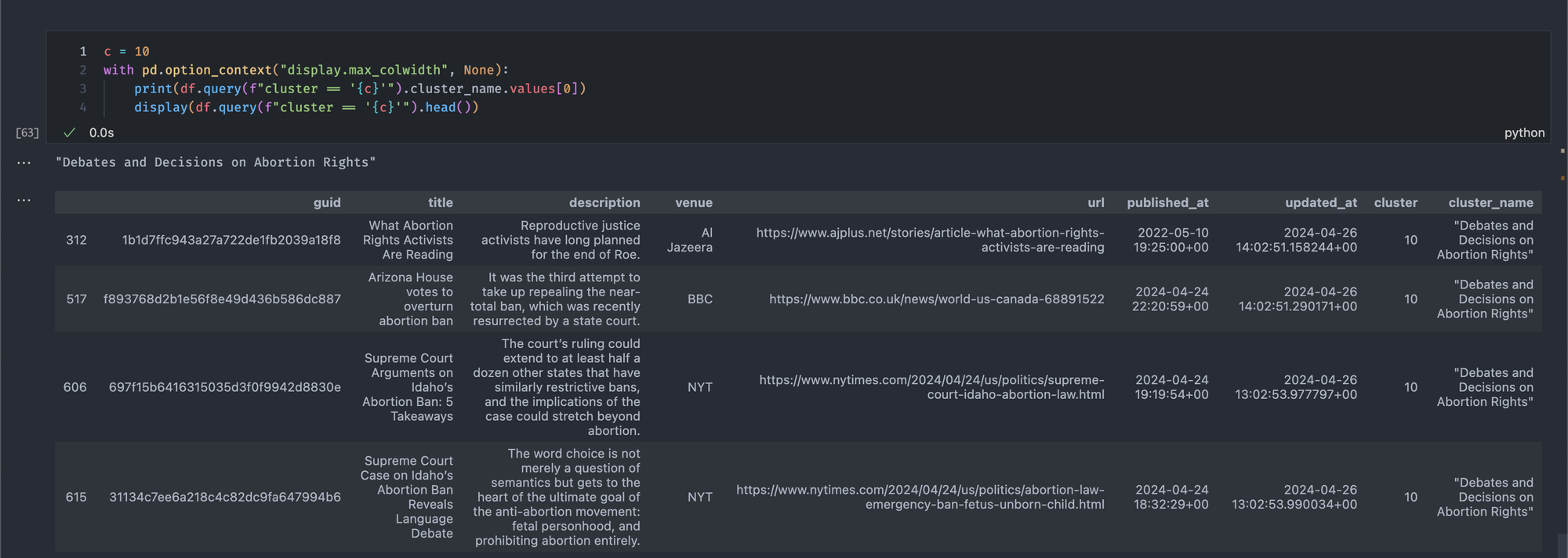
All articles seem to be related to the topic title. Yay!
Conclusion
In this short tutorial, you’ve learned how to cluster documents using OpenAI embeddings, HDBSCAN, and UMAP. I hope you find this useful. Let me know in the comments if you have any questions.
Check out the code on GitHub. You can also check this project I built with Iswar which shows this in practice.
Citation
@online{castillo2023,
author = {Castillo, Dylan},
title = {Clustering {Documents} with {OpenAI} Embeddings, {HDBSCAN}
and {UMAP}},
date = {2023-06-09},
url = {https://dylancastillo.co/posts/clustering-documents-with-openai-langchain-hdbscan.html},
langid = {en}
}