Fast & Asynchronous In Python: Accelerate Your Requests Using asyncio
A few weeks ago, I was working on a Python script to extract books’ metadata for a content-based recommender. After a couple of hours, I realized that I needed to make thousands of requests to the Google Books API to get the data. So I thought there had to be a way of speeding up the process.
As I enjoy learning, especially when it’s also a chance of procrastinating on my goals, I decided to build a project using asyncio. Afterward, feeling guilty for the time wasted, I decided to write this tutorial with what I learned in the process.
This article will show you how to use asyncio and aiohttp to do asynchronous requests to an API. It’s mostly focused on the code, apart from the short introduction below, so if you are looking for a more in-depth introduction to asyncio, check the recommendations in the references1.
asyncio in 30 Seconds or Less
asyncio is a Python library that allows you to execute some tasks in a seemingly concurrent2 manner. It is commonly used in web-servers and database connections. It is also useful for speeding up IO-bound tasks, like services that require making many requests or do lots of waiting for external APIs3.
The essence of asyncio is that it allows the program to continue executing other instructions while waiting for specific processes to finish (e.g., a request to an API). In this tutorial, you will see how to use asyncio for accelerating a program that makes multiple requests to an API.
Sequential vs. Asynchronous
So let’s get down to business. To get the most out of this tutorial, try running the code yourself. These code snippets have been tested with Python 3.8.3. You can try running them with a more recent version, but they might require some small changes.
Before running the code, you need to install the required libraries: requests, and aiohttp. Then, you can run the code snippets below in a Jupyter Notebook. If you’d like to run the snippets using a Python script, you’ll need to do some small changes to get it working.
You’ll build a sequential and an asynchronous version of a small program and compare their results and structure. Both programs will do the same:
- Read a list of ISBNs (international identifier of books)
- Request the books’ metadata to the Google Books API
- Parse the results from the requests
- Print the results to the screen.
The algorithm would look something like the diagram below.
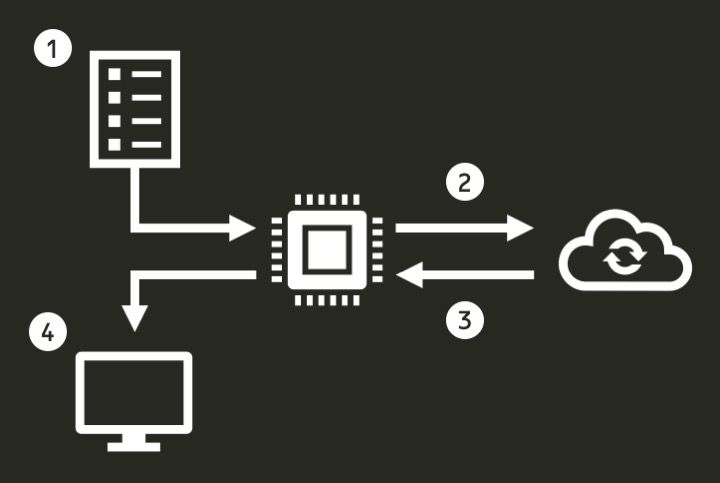
Diagram of algorithm
There’s two possible approaches for building this program. First, Option A, which executes the requests sequentially. Or, Option B, which uses asyncio to run requests asynchronously.
Option A: Sequential Algorithm
A sequential version of that algorithm could look as follows:
import os
import requests
from requests.exceptions import HTTPError
GOOGLE_BOOKS_URL = "https://www.googleapis.com/books/v1/volumes?q=isbn:"
LIST_ISBN = [
'9780002005883',
'9780002238304',
'9780002261982',
'9780006163831',
'9780006178736',
'9780006280897',
'9780006280934',
'9780006353287',
'9780006380832',
'9780006470229',
]
def extract_fields_from_response(item):
"""Extract fields from API's response"""
volume_info = item.get("volumeInfo", {})
title = volume_info.get("title", None)
subtitle = volume_info.get("subtitle", None)
description = volume_info.get("description", None)
published_date = volume_info.get("publishedDate", None)
return (
title,
subtitle,
description,
published_date,
)
def get_book_details_seq(isbn, session):
"""Get book details using Google Books API (sequentially)"""
url = GOOGLE_BOOKS_URL + isbn
response = None
try:
response = session.get(url)
response.raise_for_status()
print(f"Response status ({url}): {response.status_code}")
except HTTPError as http_err:
print(f"HTTP error occurred: {http_err}")
except Exception as err:
print(f"An error ocurred: {err}")
response_json = response.json()
items = response_json.get("items", [{}])[0]
return items
with requests.Session() as session:
for isbn in LIST_ISBN:
try:
response = get_book_details_seq(isbn, session)
parsed_response = extract_fields_from_response(response)
print(f"Response: {json.dumps(parsed_response, indent=2)}")
except Exception as err:
print(f"Exception occured: {err}")
passSequential version of algorithm
Now, let’s breakdown the code to understand what’s going on.
As usual, you start by importing the required libraries. Then, you define two variables:
GOOGLE_BOOKS_URLfor specifying the URL of the Google’s API we’ll use for the requests. This is how a request to the Google Books API looks like: https://www.googleapis.com/books/v1/volumes?q=isbn:9780002005883LIST_ISBN, which is a sample list of ISBNs for testing the program.
import os
import requests
from requests.exceptions import HTTPError
GOOGLE_BOOKS_URL = "https://www.googleapis.com/books/v1/volumes?q=isbn:"
LIST_ISBN = [
'9780002005883',
'9780002238304',
'9780002261982',
'9780006163831',
'9780006178736',
'9780006280897',
'9780006280934',
'9780006353287',
'9780006380832',
'9780006470229',
]Next, you define the extract_fields_from_responsefunction. This function takes as input the response from the API and extracts the fields we’re interested in.
def extract_fields_from_response(response):
"""Extract fields from API's response"""
item = response.get("items", [{}])[0]
volume_info = item.get("volumeInfo", {})
title = volume_info.get("title", None)
subtitle = volume_info.get("subtitle", None)
description = volume_info.get("description", None)
published_date = volume_info.get("publishedDate", None)
return (
title,
subtitle,
description,
published_date,
)Function for parsing response from the Google Books API
The parsing process in extract_fields_from_response is based on the response’s structure from the Google Books API, which looks as follows:
{
"kind": "books#volumes",
"totalItems": 1,
"items": [
{
"kind": "books#volume",
"id": "3Mx4QgAACAAJ",
"etag": "FWJF/JY16xg",
"selfLink": "https://www.googleapis.com/books/v1/volumes/3Mx4QgAACAAJ",
"volumeInfo": {
"title": "Mapping the Big Picture",
"subtitle": "Integrating Curriculum and Assessment, K-12",
...Sample response from the Google Books API
Finally, take a look at the most relevant parts of the program: how you make requests to the Google Books API.
def get_book_details_seq(isbn, session):
"""Get book details using Google Books API (sequentially)"""
url = GOOGLE_BOOKS_URL + isbn
response = None
try:
response = session.get(url)
response.raise_for_status()
print(f"Response status ({url}): {response.status_code}")
except HTTPError as http_err:
print(f"HTTP error occurred: {http_err}")
except Exception as err:
print(f"An error ocurred: {err}")
response_json = response.json()
items = response_json.get("items", [{}])[0]
return items
with requests.Session() as session:
for isbn in LIST_ISBN:
try:
response = get_book_details_seq(isbn, session)
parsed_response = extract_fields_from_response(response)
print(f"Response: {json.dumps(parsed_response, indent=2)}")
except Exception as err:
print(f"Exception occured: {err}")
passHow requests are executed to the Google Books API
There are two major pieces here:
get_book_details_seq, which is the function that executes the requests. It takes as input an ISBN and a session object4 and returns the response from the API as a JSON structure. It also handles possible errors, like providing a wrong URL or going over your daily quota of requests.- The code block under
with requests.Session() as session, is where the full pipeline is orchestrated. It iterates through the list of ISBNs, gets the books’ details, parses them, and finally prints the details to the screen.
For me, executing this process varies from 4 to 6 seconds. If you only need to do this a couple of times, you will not find much benefit from using asyncio. However, if instead of 10 requests, you need to do 10,000, having some concurrency in your program pays out. In the next section, you’ll see how to make this algorithm faster using asyncio.
Option B: Asynchronous Algorithm
An asynchronous version of the same algorithm may look something as follows:
import aiohttp
import asyncio
import os
from aiohttp import ClientSession
GOOGLE_BOOKS_URL = "https://www.googleapis.com/books/v1/volumes?q=isbn:"
LIST_ISBN = [
'9780002005883',
'9780002238304',
'9780002261982',
'9780006163831',
'9780006178736',
'9780006280897',
'9780006280934',
'9780006353287',
'9780006380832',
'9780006470229',
]
def extract_fields_from_response(response):
"""Extract fields from API's response"""
item = response.get("items", [{}])[0]
volume_info = item.get("volumeInfo", {})
title = volume_info.get("title", None)
subtitle = volume_info.get("subtitle", None)
description = volume_info.get("description", None)
published_date = volume_info.get("publishedDate", None)
return (
title,
subtitle,
description,
published_date,
)
async def get_book_details_async(isbn, session):
"""Get book details using Google Books API (asynchronously)"""
url = GOOGLE_BOOKS_URL + isbn
try:
response = await session.request(method='GET', url=url)
response.raise_for_status()
print(f"Response status ({url}): {response.status}")
except HTTPError as http_err:
print(f"HTTP error occurred: {http_err}")
except Exception as err:
print(f"An error ocurred: {err}")
response_json = await response.json()
return response_json
async def run_program(isbn, session):
"""Wrapper for running program in an asynchronous manner"""
try:
response = await get_book_details_async(isbn, session)
parsed_response = extract_fields_from_response(response)
print(f"Response: {json.dumps(parsed_response, indent=2)}")
except Exception as err:
print(f"Exception occured: {err}")
pass
async with ClientSession() as session:
await asyncio.gather(*[run_program(isbn, session) for isbn in LIST_ISBN])Asynchronous version of the program using asyncio and aiohttp
First, check the get_book_details_async function. An async keyword prepends it. This keyword tells Python that your function is a coroutine. Then, in the function’s body, there are two await keywords. These tell that coroutine to suspend execution and give back control to the event loop, while the operation the couroutine is awaiting finishes.
A coroutine is a type of generator function in Python that, instead of producing values, consumes values5. The interesting thing about it is that its execution pauses while waiting for new data being sent to it. In our case, this allows the execution of other parts of the program to continue in a seemingly concurrent manner.
In this case, the execution of get_book_details_async is suspended while the request is being performed: await session.request(method='GET', url=url). It is suspended again, while the request response is being parsed into a JSON structure: await response.json().
Next, we have the run_program coroutine. This one is simply a wrapper around the pipeline of getting a response from the API, parsing it, and printing the results in the screen. It awaits the execution of the get_book_details_async coroutine.
Finally, we have the code block under async with ClientSession() as session:. Using the asyncio.gather syntax, we tell the program to schedule all the tasks based on the list of coroutines we provided. This is what allows us to execute tasks concurrently.
For me, running this process takes around 800-1000 milliseconds.
Results
Comparing both versions, we see that the asynchronous one is around 4 to 7.5 times faster than the sequential version. If we increase the number of requests, you’ll likely get an even higher speedup. Besides, the version using asyncio is almost as simple as the sequential version. That makes asyncio an excellent option for the kind of task we reviewed in the tutorial.
Additional recommendations
Here are some tips I gathered while working with asyncio:
asynciokeeps changing all the time, so be wary of old Stack Overflow answers. Many of them are not up to date with the current best practices- External APIs will not allow you to run unlimited concurrent requests. To overcome that, take a look at asyncio’sSemaphore. It will enable you to limit the concurrency of your application.
- Not all programs can be speedup with asyncio. Research the type of issue you are facing before doing any substantial modification of code. Other alternatives might work for you (e.g., threading, multiprocessing)
- I made a complete version of the program we went through in this tutorial for getting the metadata of almost 7 thousand books. Here’s a link to it: Google Books Crawler.
Notes and References
[1] Real Python has a two of amazing articles introducing asyncio: Async IO in Python and Speed Up Your Python Program With Concurrency
[2] It is not strictly concurrent execution. But in practical terms, it looks like it is.
[3] S. Buczyński, What Is the use case of coroutines and asyncio in Python 3.6? (2017)
[4] The session object is a functionality from the requests library that allows you to persist certain parameters across sessions. This usually results in requests with lower latency. Read more here.
[5] D. Beasly, A Curious Course on Couroutines and Concurrency (2009)
[6] Cover image by Marc-Olivier Jodoin
Citation
@online{castillo2020,
author = {Castillo, Dylan},
title = {Fast \& {Asynchronous} {In} {Python:} {Accelerate} {Your}
{Requests} {Using} Asyncio},
date = {2020-03-01},
url = {https://dylancastillo.co/posts/fast-and-async-in-python-accelerate-your-requests-using-asyncio.html},
langid = {en}
}