How to Use OpenSearch in Python
OpenSearch is a free and open-source search platform created by Amazon that makes it easy to search and analyze data. Developers use it for search in apps, log analytics, data observability, data ingestion, and more.
OpenSearch began with a lot of controversy. It is a fork of Elasticsearch and Kibana that was created in January 2021 due to a change in the license of Elastic’s products. Elastic changed its policy because it believed AWS was not using its products fairly. Both companies faced significant backlash as a result of this event.
Following this conflict, AWS stopped providing clusters with the most recent version of Elasticsearch. The most recent version available is 7.10. Since then, OpenSearch has been the default option (currently on version 1.3).
Given the prevalence of AWS in many industries, it’s likely that you’ll end up using OpenSearch at some point. If you work in data, you should familiarize yourself with this technology.
Many data scientists struggle to set up a local environment or understand how to interact with OpenSearch in Python, and there aren’t many resources available to help. This is why I created this tutorial.
You’ll learn how to:
- Set up an OpenSearch cluster on your machine using docker
- Create, interact, and delete an index
- Store and search your data
Let’s get to it!
Prerequisites
Before you begin, a few things must be in place. Follow these steps:
- Install Docker.
- Download the data.
- Create a virtual environment and install the required packages. You can create one with
venvby running these commands in the terminal:
Let’s move on to the next section.
Run a Local OpenSearch Cluster
Using Docker is the simplest method for running OpenSearch locally. Run the following command in a terminal to launch a single-node cluster:
You will see a lot of text on your terminal after running this command. But it’s okay, don’t worry!
Let me describe what the command mentioned above does:
**docker run**: It’s the command you use to run an image inside -a container.**--rm**: This flag instructs Docker to clear the container’s contents and file system after it shuts down.**-p 9200:9200 -p 9600:9600**: This instructs Docker to open specific ports on the container’s network interface.**-e "discovery.type=single-node"**: This instructs Docker to set up a cluster using a single node.
Connect to Your Cluster
Create a new Jupyter Notebook, and run the following code, to connect to your newly created OpenSearch cluster.
This will connect to your local cluster. You specify the following parameters:
**hosts = [{"host": "localhost", "port": 9200}]**: this tells OpenSearch to connect to the cluster running in your local machine in port 9200.**http_auth = ("admin", "admin")**: this provides the username and password to use when connecting to the cluster. You’ll useadminfor both as this is only for local development.use_ssl=True: this tells the client to use an SSL connection. OpenSearch’s docker images use SSL connections by default, so you’ll need to set this toTrueeven if you’re using self signed certificates.**verify_certs**,**ssl_assert_hostname**, and**ssl_show_warn**: The first two security parameters that you’ll set to false, as this is a cluster running locally only used for development purposes. The last parameter prevents the client from raising a warning when initiating the connection with the cluster.
If everything went well, your output should look like this:
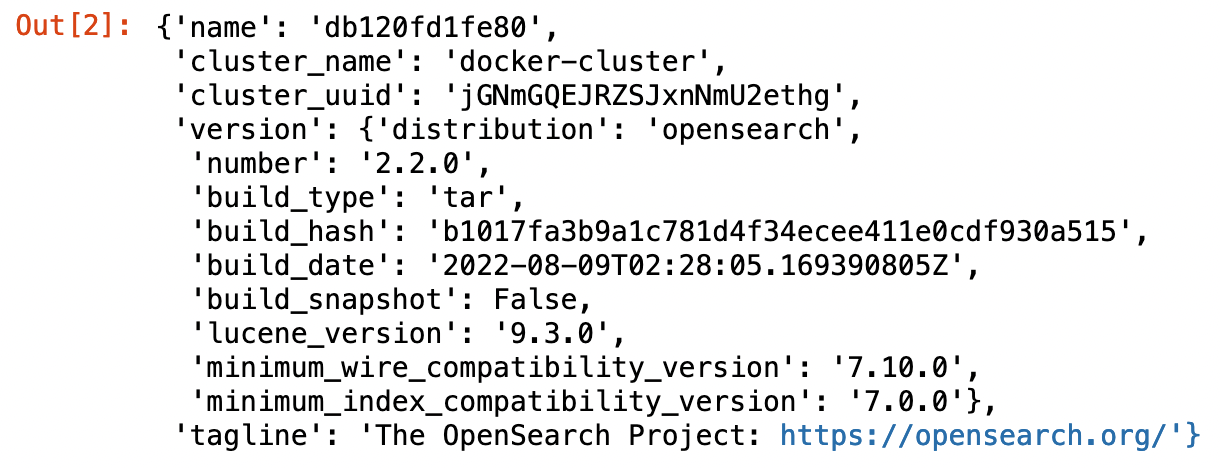 Next, you’ll read the data you’ll use in the tutorial.
Next, you’ll read the data you’ll use in the tutorial.
Read the Data
You’ll use pandas to read the dataset and get a sample of 5,000 observations. Feel free to use dataset if you want to, but not that if you do, it’ll take longer to index the data.
Next, let’s create an index to store your data.
Create an Index
OpenSearch stores and represents your data using a data structure known as an inverted index. This data structure identifies the documents in which each unique word appears.
This inverted index is why OpenSearch can form very quick full-text searches.
To index documents, you must first create an index. Here’s how you do it:
body = {
"mappings":{
"properties": {
"title": {"type": "text", "analyzer": "english"},
"ethnicity": {"type": "text", "analyzer": "standard"},
"director": {"type": "text", "analyzer": "standard"},
"cast": {"type": "text", "analyzer": "standard"},
"genre": {"type": "text", "analyzer": "standard"},
"plot": {"type": "text", "analyzer": "english"},
"year": {"type": "integer"},
"wiki_page": {"type": "keyword"}
}
}
}
response = client.indices.create("movies", body=body)This code will create a new index called movies using the cluster you set up earlier.
Lines 1 to 14 define the request’s body, specifying configuration settings used when the index is created. The mapping, which tells the index how to store the documents, is the only specified setting in this case.
There are two ways to map data fields in OpenSearch: dynamic mapping and explicit mapping. With dynamic mapping, the engine automatically detects the data type for each field. With explicit mapping, you manually define the data type for each field. In this example, you’ll use the latter.
Now you’ll start adding data to your index.
Add Data to Your Index
There are two ways to add data to an index: client.index() and bulk(). client.index() lets you add one item at a time while bulk() lets you add multiple items simultaneously.
You can use any of the two methods to add data to your index:
Using client.index()
Here’s how you use client.index() to index your data:
This code iterates through the rows of the dataset you read earlier and indexes the relevant information from each row using client.index(). You use three parameters of that method:
index="movies": this tells OpenSearch which index to use to store the data, as you can have multiple indexes in a cluster.id=i: this is the document’s identifier when you add it to the index. In this case, you set it to be the row number.document=doc: this tells the engine what information it should store.
Using bulk()
Here’s how you use bulk() to store your data:
from opensearchpy.helpers import bulk
bulk_data = []
for i,row in df.iterrows():
bulk_data.append(
{
"_index": "movies",
"_id": i,
"_source": {
"title": row["Title"],
"ethnicity": row["Origin/Ethnicity"],
"director": row["Director"],
"cast": row["Cast"],
"genre": row["Genre"],
"plot": row["Plot"],
"year": row["Release Year"],
"wiki_page": row["Wiki Page"],
}
}
)
bulk(client, bulk_data)bulk() requires the same information as client.index(): the index’s name, the document’s ID, and the document itself. But instead of adding each item one by one, you must create a list of dictionaries with all the documents you want to add to the index. Then, you pass this information and the client to bulk().
After you add the data, you can make sure it worked by counting the number of items in the index:
Your output should look like this:

Search Your Data
Finally, you’ll want to start running searches using your index. OpenSearch comes with a query domain-specific Language (DSL) that lets you tailor your searches to your needs.
Here’s an example of a search that looks for movies starring Jack Nicholson but whose director isn’t Tim Burton:
When you run this code, you should get a very long response that looks something like this:
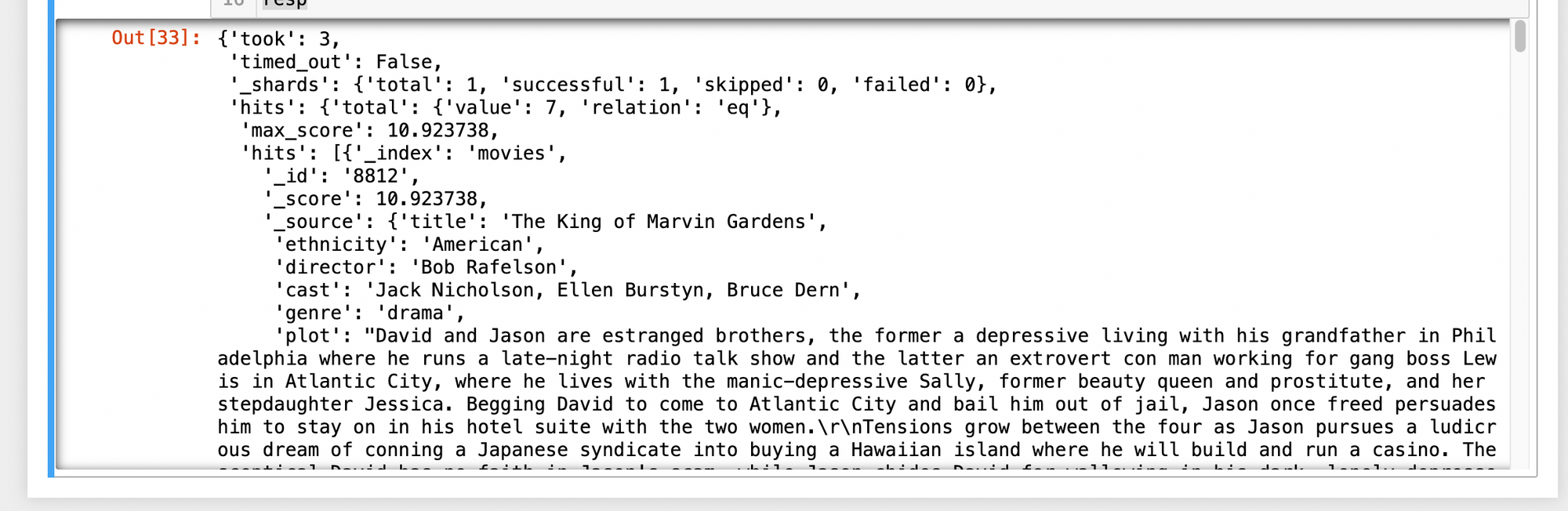
There are many ways to tailor your search queries. To learn more about it, check out the official documentation.
Delete Documents From the Index
You can use the following code to remove documents from the index:
The code above will delete the document with ID 2500 from the index movies.
Delete an Index
Finally, if, for whatever reason, you’d like to delete an index (and all of its documents), here’s how you do it:
Conclusion
This tutorial taught you the basics of OpenSearch and how to use it in Python. OpenSearch is now the default offering in AWS, so if you’re a data professional, you should familiarize yourself with it.
In this tutorial, you’ve learned:
- How to set up a local OpenSearch cluster
- How to create an index and store data in it
- How to search your data using OpenSearch
- How to delete documents and an index
If you have any questions or feedback, let me know in the comments!
All the code for this tutorial is available on GitHub.
Citation
@online{castillo2022,
author = {Castillo, Dylan},
title = {How to {Use} {OpenSearch} in {Python}},
date = {2022-08-31},
url = {https://dylancastillo.co/posts/opensearch-python.html},
langid = {en}
}