Semantic Search with OpenSearch, Cohere, and FastAPI
Semantic search is a hot topic right now. The fast-paced progress of Large Language Models (LLMs), as well as the availability and quality of embeddings, the key technology behind semantic search, have piqued the interest of many people in this field.
I’ve worked on a number of projects involving semantic search (before it was cool!), and have been closely following the progress in LLMs. So I decided to write a step-by-step tutorial that combined these two technologies.
In this tutorial, I’ll show you how to build a semantic search service using OpenSearch, Cohere, and FastAPI. You’ll create an app that lets users search through news articles to find the ones that are most relevant to their query.
Let’s get started!
Prerequisites
There are a few things you need to know to get the most out of this tutorial:
- What semantic search is.
- How OpenSearch works.
- What LLMs are.
Don’t feel discouraged if some of these concepts are new to you. A basic understanding of these topics should be enough to complete this tutorial.
In addition, you must install Docker and create an account at Cohere.
Keyword-based Search vs. Semantic Search
Search engines have evolved over time to provide users with more relevant results. In the past, search engines relied on keyword matching to deliver these results. For example, if a user searched for “AI chatbot,” the search engine would find documents that included that phrase and show them based on a ranking system like PageRank.
This method worked well for finding results that contained specific keywords but fell short when users sought information that was related to, but not identical to, their initial query. For example, a search for “machine learning” might yield more relevant results if it also considered semantically similar terms such as “artificial intelligence” or “deep learning”.
Enter semantic search. It is a more sophisticated method that takes into account factors like synonyms, user context, and concept relationships when generating search results. By considering these factors, this approach provides users with better sets of results.
Architecting a Semantic Search Service
Aside from the data extraction pipeline, which I’m not including here, the semantic search service you’ll create has four parts:
- Vectorizer: This takes care of creating numerical vectors, called embeddings, from the documents (news articles) in your dataset.
- Indexer: This adds the embeddings and the metadata such as URL, title, and author to the vector database.
- Vector database: This is a database that stores and retrieves vectors representing documents.
- Search client: This is a FastAPI-based backend service that processes the user’s query, vectorizes it, and searches the vector database for the most similar vectors.
Here’s a diagram of all the components:

Architecture diagram
Next, you’ll set up your local environment to run the project.
Set Up Your Local Environment
Follow these steps to set up your local environment:
- Install Python 3.11.
- Clone the repository with the sample app:
- Go to the root folder of the project and create a virtual environment with the dependencies using venv and pip:
Assuming all went smoothly, you should have a virtual environment set up with the required libraries and the following project structure:
opensearch-cohere-semantic-search
├── LICENSE
├── README.md
├── data
│ ├── news.csv
│ ├── news_sample.csv
│ └── news_sample_with_vectors.csv
├── notebooks
│ └── generate_sample.ipynb
├── requirements.txt
├── run_opensearch_docker.sh
└── src
│ ├── app.py
│ ├── config.py
│ ├── indexer.py
│ └── vectorizer.py
├── .env-example
└── .venv/The project is organized into several key files and directories, as described below
data/: This directory contains the project’s data. It contains the original dataset downloaded from Kaggle, and a sample, which you’ll use in the tutorial.requirements.txt: This file contains a list of Python packages required by the project and their respective versions.run_opensearch_docker.sh: This file contains a bash script used to run an OpenSearch cluster locally.src/app.py: This file contains the code of the FastAPI application.src/config.py: This file contains project configuration specifications such as Cohere’s API key (read from a.envfile), the paths to the data, and the name of the index.src/indexer.py: This file contains the code you use to create an index and insert the documents in OpenSearch.src/vectorizer.py: This file contains the code to transform the input data into embeddings..env-example: This file is an example of the environment variables you must provide..venv/: This directory contains the project’s virtual environment.
All done! Let’s get going.
Run a Local OpenSearch Cluster
Before we get into the code, you should start a local OpenSearch cluster. Open a new terminal, navigate to the project’s root folder, and run:
This will launch a local OpenSearch cluster. If everything went well, the terminal will show a long string of text. Keep the terminal open in the background and move on to the next step.
Vectorize the Articles
You’ll start by transforming the news articles into vectors (embeddings). There are many approaches you could take such as using Word2Vec, Sentence-Transformers, or LLM-based embedding services. In this case, you’ll use Cohere.
Use src/vectorizer.py for that:
import cohere
import pandas as pd
from tqdm import tqdm
from config import COHERE_API_KEY, NEWS_SAMPLE_DATASET, DATA
def main():
df = pd.read_csv(NEWS_SAMPLE_DATASET)
cohere_client = cohere.Client(COHERE_API_KEY)
model = "small"
batch_size = 96
batch = []
vectors = []
for _, row in tqdm(df.iterrows(), total=len(df)):
batch.append(row["text"])
if len(batch) >= batch_size:
response = cohere_client.embed(texts=batch, model=model)
vectors.append(response.embeddings)
batch = []
if len(batch) > 0:
response = cohere_client.embed(texts=batch, model=model)
vectors.append(response.embeddings)
batch = []
df["vector"] = [item for sublist in vectors for item in sublist]
df.to_csv(DATA / "news_sample_with_vectors.csv", index=False)
if __name__ == "__main__":
main()This code reads the news articles dataset, splits it into batches, and generates embeddings for each individual article. It works as follows:
- Lines 1 to 5 import the required Python libraries and the configuration settings from
config.py. - Lines 9 to 28 read the news articles sample, start the Cohere client, split the dataset into batches of 96 documents (as this is the maximum accepted by Cohere), and uses the client to get embeddings for each document.
- Lines 30 to 32 create a new column in the DataFrame to store the vectors and save the new dataset into your filesystem.
You can run this script by opening a terminal in src and running:
Next, you’ll create an index to store the embeddings.
Index the Vectors and Metadata
After you’ve created embeddings of each article, you’ll store them, and their metadata (title, content, description), in an index in your OpenSearch cluster.
You can use src/indexer.py for that:
import pandas as pd
from opensearchpy import OpenSearch, NotFoundError
from config import NEWS_WITH_VECTORS_DATASET, INDEX_NAME
from tqdm import tqdm
def main():
client = OpenSearch(
hosts=[{"host": "localhost", "port": 9200}],
http_auth=("admin", "admin"),
use_ssl=True,
verify_certs=False,
ssl_assert_hostname=False,
ssl_show_warn=False,
)
df = pd.read_csv(NEWS_WITH_VECTORS_DATASET)
body = {
"settings": {
"index": {"knn": True},
},
"mappings": {
"properties": {
"id": {"type": "integer"},
"title": {"type": "keyword"},
"content": {"type": "keyword"},
"description": {"type": "keyword"},
"embedding": {"type": "knn_vector", "dimension": 1024},
}
},
}
try:
client.indices.delete(index=INDEX_NAME)
except NotFoundError:
pass
client.indices.create(INDEX_NAME, body=body)
for i, row in tqdm(df.iterrows(), total=len(df)):
embedding = [
float(x) for x in row["vector"].replace("[", "").replace("]", "").split(",")
]
client.index(
index=INDEX_NAME,
body={
"source_id": i,
"title": row["title"],
"content": row["content"],
"description": row["description"],
"embedding": embedding,
},
)
client.indices.refresh(index=INDEX_NAME)
print("Done", client.cat.count(index=INDEX_NAME, format="json"))
if __name__ == "__main__":
main()This code will create a new index in your OpenSearch cluster, and store the vectors and metadata in it. Here’s how it works:
- Lines 1 to 5 import the required Python libraries and the predefined configuration settings from
config.py. - Lines 9 to 16 start the OpenSearch client.
- Lines 20 to 33 define the settings and mappings of the index you’ll create. You set
"knn": Trueso that OpenSearch knows that you’ll be using the k-NN plugin to store and retrieve vectors. Very importantly, you also need to define the size of the vector in themappings, based on the model you use. Cohere’ssmallembeddings generate vectors of 1024 dimensions. - Lines 35 to 54 create the index (and delete any previous ones), and add each document one by one. You index the
id,title,description, andembeddingfor each document.
You can run this script by opening a terminal in src and running:
So far, you’ve created embeddings for each document and indexed them in your OpenSearch cluster. Next, you’ll run a search client to interact with them.
Create a Search Client
Finally, you’ll create a search client so that users can search the articles you indexed using FastAPI. It’ll let users provide a search term, and give them back the 10 most similar documents based on that term.
The code is available in src/app.py:
import cohere
from fastapi import FastAPI
from config import COHERE_API_KEY, INDEX_NAME
from opensearchpy import OpenSearch
app = FastAPI()
opensearch_client = OpenSearch(
hosts=[{"host": "localhost", "port": 9200}],
http_auth=("admin", "admin"),
use_ssl=True,
verify_certs=False,
ssl_assert_hostname=False,
ssl_show_warn=False,
)
cohere_client = cohere.Client(COHERE_API_KEY)
@app.get("/")
def index():
return {"message": "Make a post request to /search to search through news articles"}
@app.post("/search")
def search(query: str):
query_embedding = cohere_client.embed(texts=[query], model="small").embeddings[0]
similar_news = opensearch_client.search(
index=INDEX_NAME,
body={
"query": {"knn": {"embedding": {"vector": query_embedding, "k": 10}}},
},
)
response = [
{
"title": r["_source"]["title"],
"description": r["_source"]["description"],
"content": r["_source"]["content"],
}
for r in similar_news["hits"]["hits"]
]
return {
"response": response,
}This code lets users search through the index. It works as follows:
- Lines 1 to 6 import the required Python libraries, and the configuration defined in
config.py. - Lines 9 to 20 initialize the FastAPI app, and the OpenSearch and Cohere clients.
- Lines 23 to 25 define an endpoint that provides the user with a message explaining how to use the app if they make a GET request to “/”.
- Lines 28 to 49 define a
**/**searchendpoint that accepts a query string parameter. It uses Cohere to generate an embedding from a query and then searches the OpenSearch index for the ten most similar documents. Finally, it formats the results as a user response.
To run the app, you can use uvicorn app:app --reload. You can test the app by opening your browser, navigating to localhost:8000/docs, and clicking on POST /search:
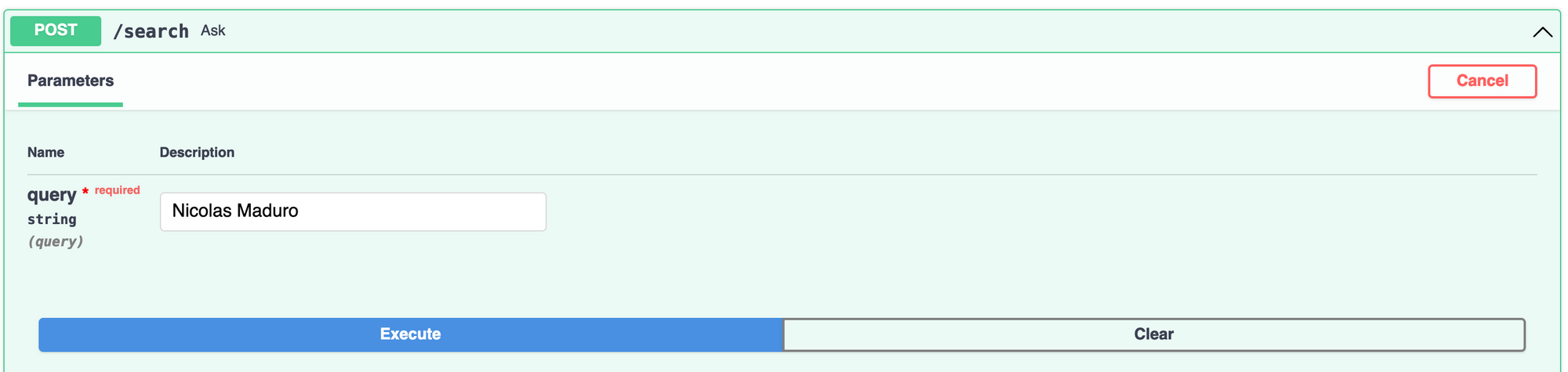
For instance, if you search for “Nicolas Maduro,” the current president of Venezuela who is widely regarded as a dictator. You’ll get results for articles about authoritarian governments or power abuses:
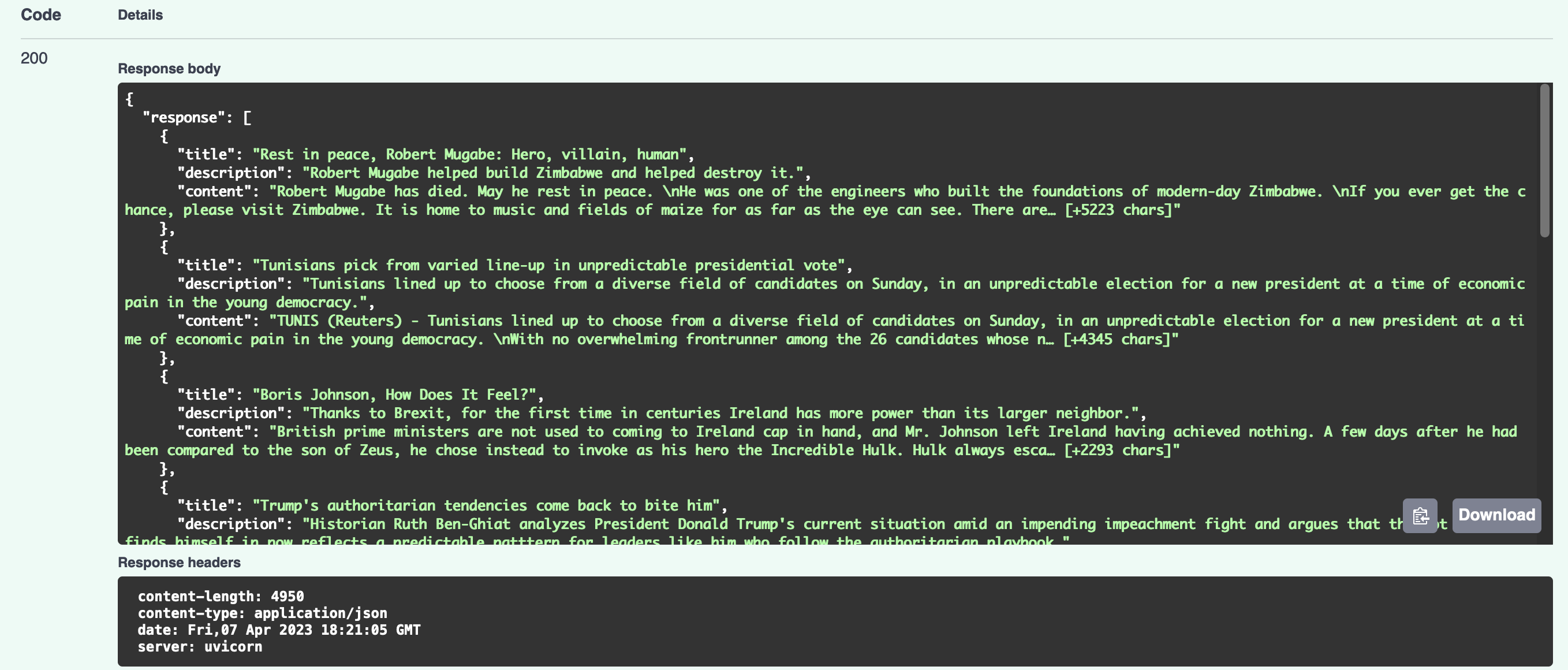
That’s it! If you want to know how to deploy this app, check out a previous article I wrote.
Conclusion
Congrats! You’ve built your own semantic search service. In this tutorial, you’ve learned:
- What is semantic search, and how it is different from keyword-based search.
- What are the main components of a semantic search service.
- How to use Cohere to vectorize text data.
- How to use OpenSearch to store embeddings.
Hope you found this tutorial useful. Let me know if you have any questions!
All the code for this tutorial is available on GitHub.
Citation
@online{castillo2023,
author = {Castillo, Dylan},
title = {Semantic {Search} with {OpenSearch,} {Cohere,} and {FastAPI}},
date = {2023-04-11},
url = {https://dylancastillo.co/posts/semantic-search-with-opensearch-cohere-and-fastapi.html},
langid = {en}
}