flowchart LR
In --> LLM1["LLM Call 1"]
LLM1 -- "Output 1" --> Gate{Gate}
Gate -- Pass --> LLM2["LLM Call 2"]
Gate -- Fail --> Exit[Exit]
LLM2 -- "Output 2" --> LLM3["LLM Call 3"]
LLM3 --> Out
Prompt chaining workflow with Pydantic AI
til
llm
pydantic-ai
workflows
To get more familiar with Pydantic AI, I’ve been re-implementing typical patterns for building agentic systems.
In this post, I’ll explore how to build a prompt chaining. I won’t cover the basics of agentic workflows, so if you’re not familiar with the concept, I recommend you to read this post first.
I’ve also written other TILs about Pydantic AI: - Routing - Evaluator-optimizer - ReAct agent - Parallelization and Orchestrator-workers
You can download this notebook here.
What is prompt chaining?
Prompt chaining is a workflow pattern that splits a complex task into multiple subtasks. This gives you better results, but at the cost of longer completion times (higher latency).
It looks like this:
Examples:
- Generating content in a pipeline by generating table of contents, content, revisions, translations, etc.
- Generating a text through a multi-step process to evaluate if it matches certain criteria
Let’s get to it!
Setup
I went with a simple example to implement a content generation workflow composed of three steps:
- Generate a table of contents for the article
- Generate the content of the article
- Update the content of the article if it’s too long
Because Pydantic AI uses asyncio under the hood, you need to enable nest_asyncio to use it in a notebook:
Then, you need to import the required libraries. Logfire is part of the Pydantic ecosystem, so I thought it’d be good to use it for observability.
TruePydanticAI is compatible with OpenTelemetry (OTel). So it’s pretty easy to use it with Logfire or with any other OTel-compatible observability tool (e.g., Langfuse).
To enable tracking, create a project in Logfire, generate a Write token and add it to the .env file. Then, you just need to run:
Logfire project URL: ]8;id=13458;https://logfire-us.pydantic.dev/dylanjcastillo/blog\https://logfire-us.pydantic.dev/dylanjcastillo/blog]8;;\
The first time you run this, it will ask you to create a project in Logfire. From it, it will generate a logfire_credentials.json file in your working directory. In following runs, it will automatically use the credentials from the file.
Prompt chaining workflow
As mentioned before, the workflow is composed of three steps: generate a table of contents, generate the content of the article and update the content if it’s too long.
So I created three Agent instances. Each one takes care of one of the steps.
Here’s the code:
toc_agent = Agent(
'openai:gpt-4.1-mini',
system_prompt=(
"You are an expert writer specialized in SEO. Provided with a topic, you will generate the table of contents for a short article."
),
)
article_agent = Agent(
'openai:gpt-4.1-mini',
system_prompt=(
"You are an expert writer specialized in SEO. Provided with a topic and a table of contents, you will generate the content of the article."
),
)
editor_agent = Agent(
'openai:gpt-4.1-mini',
system_prompt=(
"You are an expert writer specialized in SEO. Provided with a topic, a table of contents and a content, you will revise the content of the article to make it less than 1000 characters."
),
)
@logfire.instrument("Run workflow")
def run_workflow(topic: str) -> str:
toc = toc_agent.run_sync(f"Generate the table of contents of an article about {topic}")
content = article_agent.run_sync(f"Generate the content of an article about {topic} with the following table of contents: {toc.output}")
if len(content.output) > 1000:
revised_content = editor_agent.run_sync(f"Revise the content of an article about {topic} with the following table of contents: {toc.output} and the following content: {content.output}")
return revised_content.output
return content.output
output = run_workflow("Artificial Intelligence")18:54:00.987 Run workflow
18:54:00.988 toc_agent run
18:54:00.989 chat gpt-4.1-mini
18:54:02.911 article_agent run
18:54:02.911 chat gpt-4.1-mini
18:54:18.621 editor_agent run
18:54:18.622 chat gpt-4.1-miniThis code creates the agents and puts them together in a workflow. I used @logfire.instrument to make sure all the traces related to the workflow are logged within the same span. See example below:
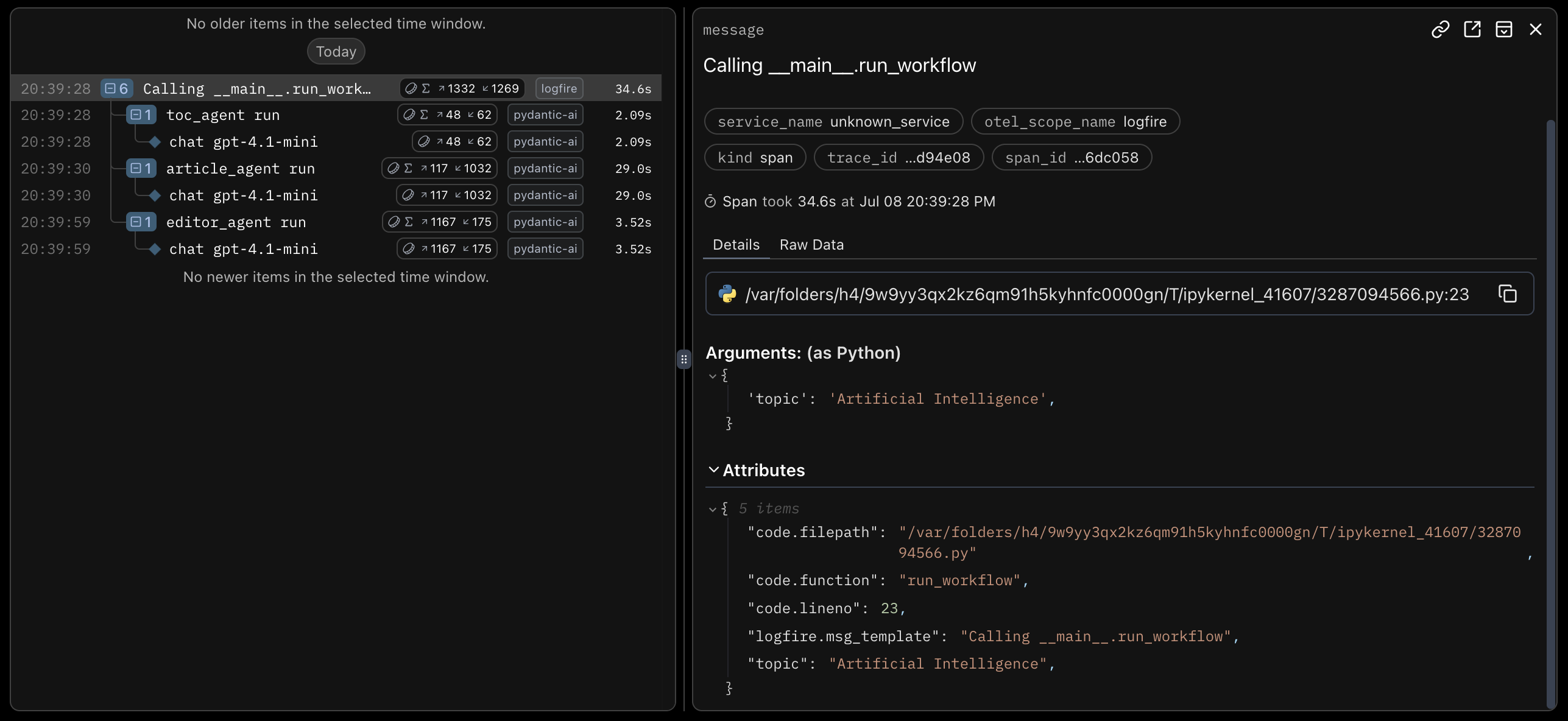
And here’s the output:
Artificial Intelligence (AI) simulates human intelligence in machines capable of learning, problem-solving, and decision-making. Originating as a formal discipline in the 1950s, AI evolved from rule-based systems to advanced machine learning and deep learning, now integral to daily life. AI types include Narrow AI for specific tasks, General AI with human-level cognition, and theoretical Superintelligent AI. Key technologies include machine learning, deep learning, natural language processing, and computer vision. AI transforms sectors like healthcare, finance, transportation, and education by automating tasks and improving decisions. Benefits include increased efficiency and innovation, while challenges involve data privacy, bias, job displacement, and transparency. Future trends highlight explainable AI, edge computing, and human-AI collaboration. Ethical concerns focus on accountability, fairness, and user privacy. Responsible AI development promises a transformative, inclusive future.That’s all!
You can access this notebook here.
If you have any questions or feedback, please let me know in the comments below.
Citation
BibTeX citation:
@online{castillo2025,
author = {Castillo, Dylan},
title = {Prompt Chaining Workflow with {Pydantic} {AI}},
date = {2025-07-08},
url = {https://dylancastillo.co/til/prompt-chaining-pydantic-ai.html},
langid = {en}
}
For attribution, please cite this work as:
Castillo, Dylan. 2025. “Prompt Chaining Workflow with Pydantic
AI.” July 8. https://dylancastillo.co/til/prompt-chaining-pydantic-ai.html.